
2024 Backward Pass: The Definitive Guide to AI in 2024
Your ultimate recap of AI for 2024

The original report in PDF can be downloaded here: https://translinkcapital.docsend.com/v/c98t5/backward_pass
OPENING REMARKS
I began this document in September as a way to organize my personal notes around everything in AI this year. Later, I realized there might be value in sharing a more comprehensive year-in-review with a broader audience. What you’re reading now is the result of that effort.
The goal of this paper is to present the most thorough analysis of AI’s development for this year, It encompasses many of my personal thoughts on the space and draws upon insights gathered from conversations with researchers, portfolio companies, and over 300 AI startups. It also leverages the vast network of corporate relationship that my firm Translink Capital has built over the past 16 years.
The review is structured into four sections, corresponding to each of the layers in the AI technology stack:
Infrastructure layer
Foundational model layer
Tooling layer
Application layer
Each section is further divided into three parts:
I. Key takeaways
II. Future trends to watch
III. Noteworthy startups
Finally, we conclude with two sections on investment and M&A and other general AI trends.
As a venture investor working for a multinational firm, I’m incredibly fortunate to have a job that allows me to see across different layers and geographies of the AI ecosystem. This broad perspective gives me the opportunity to identify patterns that might not be immediately apparent to those more deeply focused in one specific area. By capitalizing on the opportunities afforded to me, I hope to contribute what I can to the understanding of this field.
I know how valuable everyone’s time is, so I’ve put in my best effort to ensure this is worth reading. I hope you find it helpful, and I encourage you to share it with anyone who might benefit from it.
Sincerely,
Kelvin
INTRODUCTION
What a remarkable year it was for AI.
The long-anticipated AI revolution is no longer a distant vision but a present reality. Since the 1950s, when Alan Turing first proposed the Turing Test and Frank Rosenblatt pioneered the first artificial neural network, AI has been heralded as a transformative force capable of reshaping society. Yet, its journey has been far from smooth – AI went through multiple "winters" from the 1970s through the early 2000s, periods where interest and funding dried up. Only in recent years, with breakthroughs like ImageNet (2009), AlphaGo (2015), Transformers (2017), and ChatGPT (2022), has AI truly regained its momentum.
This year marked a watershed moment where innovation, investment, and adoption have converged like never before. AI has moved beyond the confines of research labs and academic communities to become a central topic in boardrooms, political debates, and dinner table conversations. Over $60 billion in venture capital flowed into the sector this year, with AI investments now accounting for over one-third of all VC activity – surpassing traditionally dominant industries like healthcare and consumer.
For only the third time in modern history, the entire tech infrastructure and compute stack is being reimagined from the ground up. Nvidia, the biggest beneficial of this transformation, has surged to become the world’s most valuable company, growing its market cap tenfolds to $3 trillion within a mere 24 months. Meanwhile, OpenAI, despite navigating internal turmoil, has set new historic records, reaching a $4 billion ARR run rate in just three years of commercialization – a pace at least three times faster than Amazon, the previous record-holder.
Enterprises, too, are embracing AI at scale. A year ago, a JP Morgan survey revealed that only 5% of enterprises had generative AI applications in production. Today, that percentage has more than tripled. While many implementations remain in the proof-of-concept (POC) stage, some use cases—like code generation and customer support – have seen widespread adoption. At Google, more than a quarter of all new code is generated by AI, and Klarna’s AI customer support agent can do the work of 700 human reps. These examples show that AI is moving from promise to practice and is starting to deliver tangible bottom-line results to businesses.
Yet, despite these advancements, skepticism remains. Some have begun to question the sustainability of the current AI investment boom. In June, Sequoia published an article titled “AI’s $600B question”, challenging the ROI of massive infrastructure spending. Shortly after, Goldman Sachs echoed similar concerns in an article “Gen AI: Too Much Spend, Too Little Benefit”. Perhaps unsurprisingly, over 40% of asset managers believe we’re now in an AI bubble.
Regardless of where one stands in this debate, one fact is indisputable: the pace of AI innovation and adoption this year was unprecedented. Few years in modern history have seen such a concentrated burst of technological progress and investment as we saw in 2024. This is more than a technological revolution; it is a societal revolution. And we are not merely spectators to this revolution but active participants—a rare opportunity we must responsibly embrace.
What an extraordinary time to be alive.
INFRASTRUCTURE LAYER

“The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective,
and by a large margin”
– Rich Sutton, The Bitter Lessons
I. Key Takeaways:
We are witnessing the dawn of a new infrastructure paradigm. In modern history, only twice before has a completely new infrastructure and compute stack been redefined entirely – the internet and telecom boom of the late 20th century, and the rise of cloud computing and SaaS. Now, with GenAI, we are entering into a third phase.
But it is still early earnings. During the internet buildout, over $1 trillion in capital was invested between 1996 and 2001. The current generative AI buildout has seen only $300 billion invested over the past two years. By this measure, we are still in the early innings. (For more detail on this topic, see my in-depth piece here comparing the current AI cycle with the dot-com cycle).
Demand for inference is just getting started. While demand for training may be maturing as we reach scaling limits (more on this later), demand for inference is just getting started. Broadly speaking, there are three reasons for this:
Early Adoption. Generative AI adoption by enterprises is still in its infancy, but accelerating rapidly. OpenAI serves as a useful indicator: despite a >10x reduction in per-token API costs over the past year, its revenue quadrupled from a $1b to $4b run-rate, implying a ~40x increase in usage.* Such level of growth indicates that we’re still in the early stages of adoption.
Multi-modal use cases coming soon. Most GenAI applications today are text-based. Multimodal use cases (e.g., text-to-video, text-to-3D) remain largely untapped, but are far more compute-intensive. For example, generating an AI video requires roughly 100 times the energy of an equivalent text-based document. If entire industries such as advertising, media, and entertainment adopt GenAI, that would create an exponential demand for inference. With the latest advancements in multimodal AI, this may be coming soon.
Evolving model architecture. Newer models, such as OpenAI’s o1 are shifting to more inference-time reasoning (also known as test-time compute) incorporating chain-of-thought and reinforcement learning. This architecture essentially gives models extra processing time to think and complete tasks. But this also means more computational requirements. For example, the new o1 model costs 3-4x more per token than GPT-4o. As more workloads transition to this model architecture, the demand for inference will continue to rise.
It is difficult to measure the ROI of the current infrastructure buildout. This summer, Sequoia published an article questioning where the $600 billion revenue was to justify the current AI infrastructure build out. A plausible explanation is that much of today’s compute is powering internal initiatives rather than new revenue-generating products – initiatives like Notion’s GenAI features or Klarna’s AI customer support agents. These projects drive operational efficiencies rather than net new revenue, making their ROI harder to quantify. For context, $600 billion is just 0.6% of the global $100 trillion GDP— which likely underestimates AI's long-term potential.
The AI cloud market is getting increasingly fragmented.
While hyperscalers (Amazon, Google, Microsoft) continue to dominate the AI cloud market today, emerging players like CoreWeave, Lambda Labs, and Tensorwave are offering cost-effective, specialized AI infrastructure. Brendan Burke from Pitchbook estimates this new AI cloud market to be $4 billion and growing to $32 billion by 2027.
Chipmakers like Nvidia and AMD are investing in these specialized providers as well. One reason is that these chipmakers are seeking to reduce their reliance on hyperscalers, who are simultaneously developing in-house chips. For example, Google’s TPU chips are now being adopted by companies like Apple. Further fragmentation in the AI cloud market appears likely.
AI hardware startups face high CapEx requirements.
A growing number of startups are designing custom ASIC chips for AI workloads (e.g., Groq, Cerebras). These companies face significant capital requirements for not only chip development but also for data center buildouts.
The latter is necessary because hyperscalers, with their own chip R&D efforts, are unlikely to adopt third-party startup chips in their own data centers. For example, chip startup Groq recently announced they were building their own inference data center in Saudi Arabia in partnership with Amarco Digital.
It remains to be seen if these startups can meaningfully capture market share from incumbents. Among startups so far, Cerebras seems to be the most ahead with $136 million of revenue in 1H 2024, but that’s still only 0.1% of Nvidia’s data center revenue.
* This estimate excludes OpenAI’s B2C subscription revenue, but the overall trend is directionally accurate.
II. Future Trends to Watch:
Data Center 2.0. Currently, data centers account for approximately only 1-2% of global electricity usage, but this figure is projected to rise to 3-4% of total power by 2030, driven largely by AI (In the US, this figure is closer to 8%). Overall, McKinsey estimates data center capacity to grow at a 22% CAGR between now and 2030.
AI-specific data centers differ significantly from traditional cloud data centers due to their higher power density, which drives the need for innovations like next-gen liquid cooling. The idiosyncratic demands of AI training and inference also require high-bandwidth, low-latency networking. This has driven the need for next-gen networking and interconnect to reduce bottlenecks in multi-GPU clusters.
AI itself can be used to optimize data centers, such as in predictive maintenance, dynamic workload allocation, and energy efficiency. For example, Phaidra is a startup that is working on autonomous control cooling systems in data centers using RL.

Nvidia’s dominance in hardware. Nvidia is now the world’s most valuable company with 40% of the gains on Nasdaq this year attributable to this one company alone. However, history offers few examples of an incumbent maintaining 90%+ market share from start to finish.
Nvidia will likely continue to dominate for the foreseeable future but there’s likely to be more competition. One contender is AMD - AMD’s data center business today is only 10% the size of Nvidia’s ($3.5 billion vs. $30.8 billion) but growing 122% year-over-year. The company is also making traction with large enterprises – for example, OpenAI recently announced they will start using AMD’s MI300 year and Lenovo says demand for AMD’s MI300 is record high.
Another major source of competition are the hyperscalers themselves. One advantage they have is their massive in-house demand for AI training and inference. Of the CSPs, Google has the biggest lead, with the new TPU V5p delivering 2x more FLOPs and 3x more high-bandwidth memory (HBM) than the previous version.
More attention paid to edge AI and edge/cloud collaboration. Here’s a fun fact: less than 1% of global compute capacity (measured in FLOPs) is owned by the hyperscalers. While this might seem surprising at first, it makes sense when you consider the sheer number of edge devices, including laptops and smartphones. Unlocking this latent power could be a gamechanger. Already, we’re witnessing an explosion of small language models (SLMs) that can be deployed on edge devices.
Some experts believe that up to half of all AI workloads can be eventually moved from the cloud to the edge. One early idea I’ve seen is to build a cloud/edge router, which can dynamically route AI workloads between the cloud and edge devices based on criteria such as power, cost, and latency requirements. Finally, Edge AI can also be helpful in speculative decoding by reducing the volume of data sent to the cloud for processing.
China’s progress in AI. Export controls around AI chips may hamper China’s progress in the short term. But longer-term, it may force China to be more creative on both the infrastructure and model side. For example, it was recently revealed that China had trained a single model across multiple data centers and GPU architectures, the first time to do so by any country. Despite limitations in compute, Chinese LLMs have shown that they can compete with the best IS models. In particular, Alibaba’s Qwen models and DeepSeek models have shown they can match Western models such as GPT-4o. This shows that while hardware restrictions may pose some challenges, Chinese labs are finding ways around it and are continuing to keep pace.
AI’s Impact on Sustainability: Hyperscalers have made climate commitments by 2030. Microsoft, for instance, has set an ambitious goal to become carbon negative by 2030. However, the rapid growth in AI energy consumption is pushing these commitments in the wrong direction. For example, Microsoft recently reported a nearly 30% increase in CO2 emissions since 2020, driven primarily by data center expansion. Similarly, Google’s greenhouse gas emissions in 2023 were 50% higher than in 2019, largely due to AI data centers as well. We think this trend will force enterprise decision-making to pay more attention in sustainability. In the long term, those that want to understand AI will need to understand the energy market as well.
III. Noteworthy Startups:
AI Cloud and Compute:
Coreweave, Crusoe, FoundryML, Lambda labs, Rescale*, SF Compute, Shadeform*, Tensorwave*, Together AI
AI chip companies:
Blaize, Cerebras, D-Matrix, Etched, Groq, Graphcore, Lightmatter, Rebellions, SambaNova, Tenstorrent, Hailo
Data center peripherals:
Celestial AI, Corintis, Liquidstack, Jetcool, Phaidra, Thintronics*, Xconn Technologies*
* Denotes Translink Capital Portfolio Company
MODEL LAYER

“Machine intelligence is the last invention that humanity will ever need to make”
– Nick Bostrom
I. Key Takeaways:
Growing attention paid to small language models (SLMs). Last year, we anticipated a growing trend in SLMs, but their rapid progress has surpassed even our expectations. Today, a 3B parameter model can match the performance of the original 175B ChatGPT model, a more than 50x improvement in parameter efficiency in just 24 months. This remarkable progress stems from better compression techniques (e.g., distillation, quantization, pruning) and the use of high-quality synthetic data. Research from a 2023 paper “Beyond Neural Scaling Laws” demonstrated that by carefully curating datasets and removing low-quality data, it’s possible to achieve better performance with a much smaller footprint. This is the core idea behind SLMs.
Consequently, edge AI is becoming more viable. As SLMs performance improves and edge hardware (CPUs, NPUs) becomes more powerful, deploying AI workloads at the edge becomes increasingly feasible. Today, a 7B model can run efficiently on a laptop. Notable examples of SLMs include Microsoft's Phi-3 model , Google's Gemini Flash, and Llama 1B and 3B models. Edge AI also has the added benefit of improved privacy & security, lower latency, and cheaper costs. This is especially good for use cases like real-time speech recognition or in offline settings. For a comprehensive review of on-device language models, check out this paper by Meta and Nexa AI.
We are shifting towards a network of models. The architecture of LLMs is evolving from large monolithic system into distributed networks of smaller, specialized models (akin to a MoE approach). This involves a parent model orchestrating tasks across these smaller, targeted models. Recent research from Meta demonstrates that using multiple smaller models in parallel can consistently outperform a single large model. This approach mirrors the human brain, which is not a single uniform structure but comprised of specialized regions like the hippocampus (memory), frontal lobe (logic), and occipital lobe (vision). We also believe this architecture will also apply to AI agents (more on this later).
Models are moving towards more inference-time reasoning. OpenAI's latest o1 model signals the shift toward inference-time reasoning using techniques like chain-of-thought and reinforcement learning. (A good summary can be found here). The o1 model learns optimal paths through trial and error, much like human problem-solving involving a lot of self-reflection and error correction. This allows the model to excel in complex reasoning tasks, such as math, coding, and scientific queries. However, this capability comes at a cost, with o1's per-token price being 3-4 times higher than GPT-4o. Another example of this model is R1-lite-preview by Chinese lab DeepSeek. Unlike o1's condensed summaries, R1-Lite-Preview shows users its complete chain-of-thought process in real-time. This growing emphasis on inference-time reasoning will likely increase demand for latency-optimized compute.
OpenAI experienced internal turmoil. This year, OpenAI experienced a lot of internal upheaval, including the abrupt ousting and subsequent reinstatement of Sam Altman as CEO. Among the original founders, only Greg Brockman and Wojciech Zaremba remain, while key figures like Ilya Sutskever, John Schulman, and Mira Murati have all left. Despite these challenges, OpenAI raised $6.5 billion at a $150 billion valuation in its latest funding round and is on pace to becoming the fastest growing technology company in history, far outpacing that of Amazon, Google, and Meta.

Meta open-source strategy is paying off. Meta continues its bold open-source approach, with Zuckerberg committing billions to Llama and Meta's broader generative AI initiatives. This approach is proving effective, with Llama models approaching 350 million downloads this year – representing more than a 10x increase from last year. On the consumer front, Meta is integrating their LLMs into existing consumer applications like Facebook and Instagram to prevent competitors from building standalone LLM interfaces like ChatGPT or Perplexity. On the enterprise front, Meta is already working with large enterprises such as AT&T, DoorDash, and Goldman Sachs. It appears the gap between closed-source proprietary models and open-source models has significantly narrowed, largely thanks to Meta’s efforts.
Over the past year, the performance gap between OpenAI and other research labs has narrowed. While OpenAI still leads, its dominance is less pronounced. Among startups, Anthropic stands out for its impressive progress in model upgrades, product launches, and talent acquisition, and is rumored to be approaching $1 billion in revenue run rate. It appears that first-mover advantage may be less enduring in the age of AI. One hypothesis is that in today’s interconnected world, mature communication infrastructure such as the internet and social media enables proprietary techniques and knowledge to disseminate faster than ever, decreasing technological moats. As a result, model performance increasingly hinges on access to capital and compute rather than any proprietary techniques. In this vein, one startup to watch for in the coming year is xAI – they already own one of the largest supercomputers in the world with over 100k H100s (soon to be 200K according to Musk). Musk has hinted that their upcoming model, Grok 3, could already be SOTA and comparable to GPT-4o.
Foundational model companies are likely to remain unprofitable in the short run. According to The Information, OpenAI’s total compute expenses for training and inference is expected to be $5 billion—exceeding its revenue of $4 billion. Assuming that inference and hosting costs make up the majority of the cost of goods sold, OpenAI operates at a gross margin of around 40%. This is in line with we hear from other foundational model companies but significantly lower than the typical margins seen in software businesses.
One reason for the low margins is the ongoing token price war among model providers, which has driven prices down by more than 10x this year. Outside of compute costs, other expenses appear to be relatively modest, with employee salaries, general and administrative (G&A) expenses, and sales and marketing together accounting for only 40% of revenue. Looking ahead, it will be interesting to see if foundational model companies can eventually achieve software-like margins as the industry matures. Regardless, we believe break-even will not be achieved anytime soon. (link to below diagram)
Finally, as model architectures evolve towards more inference-time reasoning, the cost structure may shift—reducing CapEx for training but increasing OpEx for inference. This transition could further impact margins and delay GAAP profitability.

Growing need for model companies to diversify. As the foundational model layer becomes increasingly commoditized, AI labs may need to diversify their businesses. Token prices are dropping, but rising adoption and revenue growth are helping to offset this decline for now. For example, despite token prices dropping significantly, OpenAI is still projected to 4x its revenue this year, and Anthropic is rumored to be growing at 10x. In the longer term, however, model companies may need to consider vertical integration to offset commoditization at the model layer.
In the infrastructure layer, OpenAI is developing its first in-house chip in partnership with Broadcom and TSMC. In addition, it’s collaborating with Microsoft on "Project Stargate," a 5 GwH $100 billion data center initiative.
In the application and tooling layer, OpenAI is expanding into new products such as ChatGPT search, a Perplexity-like search tool, and OpenAI Swarm, a framework for building agents. To ensure long-term growth, foundational model companies may need to shift from purely providing models to developing tools and end-user applications.
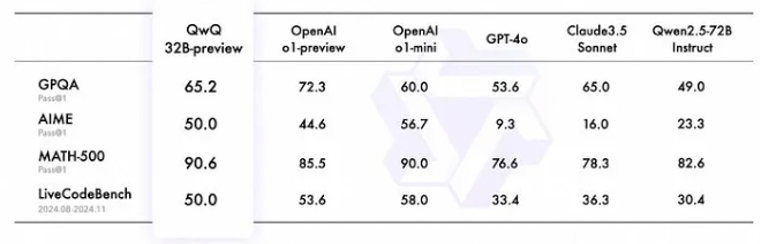
Models from China are getting much better. Chinese AI labs continue to produce impressive models, such as Alibaba’s Qwen family and Deepseek. The newest Qwen 2.5-Coder Series and QwQ-32B-preview from Alibaba are amongst the top open-source code models, matching the capability of OpenAI and Anthropic models. Both the QwQ-32-B preview and Deepseek’s R1- beat OpenAI’s o1 on popular benchmarks like MATH and AIME.
These improvements are driven by several factors. First, the competition among Chinese LLMs is fierce, even more so than the US. For example, Qwen-long tokens currently cost 0.5RMB ($0.07) per 1M tokens, a tiny fraction of the cost of its western counterparts. Chinese AI labs are particularly skilled at optimizing inference costs, a necessity given their more limited access to compute compared to Western labs. Second, data labeling and instruction-tuning (including RLHF) are significantly cheaper in China, providing an additional cost advantage. Over time, these two advantages plus others (government support, growing talent pool), could further narrow the performance gap between Chinese and Western models.
II. Future Trends To Watch:
Scaling laws could soon plateau. Recent developments suggest that scaling laws, which have historically driven model improvements through larger pre-training datasets, may soon reach their limits. Ilya Sutskever also recently expressed this view in an interview with Reuters. Around the same time, The Information published an article discussing how OpenAI’s next flagship model Orion, might not achieve the dramatic performance leaps seen in earlier iterations. This shift signals that straightforward scaling may be giving way to a new paradigm of model innovation.
New paradigm of model development: reasoning over pre-training. Going forward, model performance will hinge less on sheer amounts of pre-trained data and more on advanced reasoning capabilities at inference time. Models like o1 are using chain-of-thought and reinforcement learning which gives models more advanced reasoning capabilities. Beyond the obvious performance benefits, another benefit is that it allows customers to tailor model selection depending on the complexity of tasks. Tasks requiring sophisticated reasoning, such as a copilot for M&A negotiations, can choose to maximum inference-time reasoning. Simpler tasks, like summarization, may seek to minimize it instead. This approach gives the end customer more flexibility and can help to reduce overall costs.
The role of synthetic data. As we run out of publicly available training data, synthetic data will play a more prominent role. Synthetic data is being used more both in pre-training and post-training. Both the smaller Microsoft Phi SLMs and the largest models by OpenAI and Anthropic incorporate synthetic data into their training. However, preserving the distribution and entropy of the synthetic dataset to ensure model robustness is the challenging part.
Unsupervised / Reinforcement learning’s role in model development. Now that LLMs have some base intelligence built in, we believe RL will play a bigger role in their development. Genie (awarded best paper at ICML 2024) demonstrated this by creating a 11B parameters “world foundational model” that could generate interactive environments from unsupervised training from unlabeled internet videos. Such type of training without any ground-truth or labeled data will be the future of large model development. Over time, models will start to self-improve in a positive feedback loop, unlocking new possibilities that didn’t exist before.
The evolution of LLMs mirrors stages of human cognitive development. The first phase, mostly reliant on scaling and pre-training, is akin to the early development of a fetus or a newborn’s brain—focused on expanding and building foundational structure. Now, we are entering a second phase, where the model’s "toddler-like" brain expand beyond its organic, foundational base. In this stage, it grows smarter through trial-and-error learning, observation, and active exploration of its environment – what is effectively RL.
Advancement in multimodal AI. Multimodal AI is poised to become the next major driver of compute demand. Though adoption is still in its early stages, it is scaling rapidly. OpenAI’s Sora captured captivated the industry when it was released earlier this year. Shortly after, startups like Runway, Luma, Pika Labs, and Genmo have come up with their own text-to-video models. However, usage so far has been mostly limited to the prosumer market as the models lack the robustness required for the enterprise. On the other hand, voice/text-to-speech applications are beginning to gain significant adoption among enterprises. These include applications such as content creation and customer support. Elevenlabs, one of the leaders in this space, is rumored to be approaching $100 million in revenue run-rate. Another public company, Soundhound, (Translink portfolio company) is forecasted to generate $155-175 million in 2025.
Rise of specialized models. As general-purpose models get bigger, we expect a parallel rise in specialized models. These models may not always be text-based. Some of the more interesting areas include:
Time-series models – Foundational models for time-series analysis, like Amazon Chronos, treat time-series data as a "language" that can be modeled using a transformer architecture. One of the key strengths of time-series models is their ability to apply transfer learning – leveraging diverse datasets from different domains to improve generalizability. We believe foundational models for time series forecasting represents an exciting frontier yet to be fully explored. The main challenge, however, lies in obtaining sufficient training data. Unlike general purpose LLMs where one can rely on the public web for pretraining data, most time-series data is probably locked up within enterprises.
Physics/world models – By definition, large language models have limited inductive biases – and hence – limited understanding of real-world physics. To address this, companies like World Labs are developing models that can understand and interact with the 3D physical world, similar to human spatial intelligence. This is important in areas like robotics. This undertaking is particularly important but challenging, as we believe the world of physics operates in a far higher-dimensional space compared to the world of language. Consider a seemingly simple action like dropping a ball from a 100-meter building: while gravity (9.8 m/s²) is a known fundamental factor, many other elements such as the ball's weight, air resistance (elevation, humidity, etc.), wind, etc. come into play. Accounting for these stochastic factors makes understanding and simulating the physical world exceptionally challenging.
Another example of a world model is Microsoft’s Aurora model - a foundational model for the atmosphere pre-trained on over 1M hours of weather and climate data. In under a minute, Aurora produces 5-day global air pollution predictions and 10-day high-resolution weather forecasts that outperform state-of-the-art classical simulation tools. While its most obvious impact is better weather forecasting, there are more potential applications such as insurance and risk assessment, financial trading, and agriculture management.
Biology models - Biology-focused foundational models, such as AlphaFold 3, represent a groundbreaking advancement in structural biology. These models can accurately predict the joint structures of complex biological molecules, including proteins, nucleic acids, and small molecules, enabling scientists to generate entirely novel protein sequences. Before the advent of models like AlphaFold, determining a single protein structure could take a PhD student the entirety of their research years—typically 4-5 years. In contrast, AlphaFold has predicted over 200 million protein structures in under a year, an achievement that has fundamentally transformed our ability to understand the building blocks of life. As these models evolve, they’ll revolutionize fields such as drug discovery and personalized medicine. For further readings on this topic, please see this Forbes article by Rob Towes from Radical Ventures.
Longer-term, foundational models can be used to conduct scientific research and discover new knowledge. One example of this potential is “The AI Scientist” developed by Tokyo-based Sakana AI. The AI Scientist is a comprehensive system for automating scientific discovery. It automates the entire research lifecycle, from generating novel research ideas, writing and necessary code, executing experiments and presenting the finding in an academic report. Just as AI is starting to learn coding and generate software by itself, we believe AI’s emergent capabilities will expand to the broader domain of scientific knowledge and discovery. Such advances could fundamentally reshape the trajectory of human progress by accelerating the pace of discovery across multiple scientific disciplines.

III. Noteworthy Startups:
Foundational models / Research labs:
01.AI, Anthropic, Deepseek, H Company, Imbue, Minimax AI, Mistral, Moonshot AI, OpenAI, Reka AI, Safe SuperIntelligence, Sakana AI*, Stability AI, xAI, Zhipu
Small Language Models (SLMs):
Arcee.ai, Bespoke labs, Nexa AI, Predibase
Multi-modal (image and video):
Black Forest Labs, Genmo, Higgsfield, Luma AI, Midjourney, Pika labs, Runway ML, Stability AI, Tavus, Twelve Labs
Multimodal (voice):
AssemblyAI, DeepL, Deepgram, Elevenlabs, PlayHT, Poly AI, Resemble AI, Suno, Symbl.ai, Udio
Specialized foundational models:
Archetype AI, Cradle, CuspAI, EvolutionaryScale, Formation Bio, Generate:Biomedicines, Hume AI, Illoca, Luminance, Nabla Bio, Orbital Materials, Pantheon AI, Physical Intelligence, Silurian AI, Synthefy, World Labs
* Denotes Translink Capital Portfolio Company
TOOLING LAYER

“Genius is one percent inspiration, ninety-nine percent perspiration.”
- Thomas Edison
I. Key Takeaways:
RAG is the dominant technique approach that most companies use today. According to a recent report by Menlo VC, retrieval-augmented generation (RAG) adoption has increased to 51%, up from 31% last year. Meanwhile, fine-tuning remains uncommon, with only 9% of production models being fine-tuned. As underlying foundational model continue to improve, we anticipate this trend will continue to favor RAG.
RAG offers significant challenges but also with its own set of challenges. The main advantage of RAG lies in separating the model's reasoning plane from the data plane, allowing responses to be grounded in live, real-world data and minimizing the risk of hallucinations. However, RAG still faces issues such as a lack of domain-specific knowledge and insufficient context, which can lead to less accurate retrieval. Optimizing chunking and retrieval remains more art than science at this point, with the last mile proving especially difficult to get right.
Many are combining deterministic-based structures with RAG to help improve performance. To address some of these challenges, many companies are incorporating deterministic structures or ontologies alongside RAG to enhance performance. Knowledge graphs, for example, add a layer of structured semantic relationships between data points, making it easier to retrieve precise and relevant information for a given query. This stands in contrast to traditional RAG, where similarity is often based solely on distance between data points, which lacks deeper semantic understanding. Incorporating these structures can improve the overall accuracy of the retrieval, important particularly in domains where accuracy is critical such as healthcare, financial services, and legal.
More enterprises are opting to build solutions in-house. The Menlo report shows that nearly half of all GenAI solutions are now developed internally, up from just 20% last year. One of the most common reasons we’ve heard for why enterprises opt for in house is because they’re reluctant to give up their data to third parties. Another is the desire for greater customization to meet specific business needs. With open-source models closing the gap against closed-source models, we expect the trend towards in-house to continue.
The biggest bottleneck for enterprises is often the data curation and preparation stage. It is well known by now that AI teams spend most of their time on data preparation, with a minority of time for actual model development and deployment. Most of the data available to organizations is in the form of unstructured data, which makes up ~80% of total data today. This can be in the form of emails, documents, contracts, websites, social media, logs, etc. Transforming the data into a useable format for machine learning deployment requires extensive cleaning and standardization. Once the data is collected and cleaned, it must be then vectorized, typically by leveraging a vector database. These steps are not trivial and require deep technical and domain expertise.
Monetization in the tooling layer can be challenging at times. Monetization is often difficult due to intense competition, the availability of open-source alternatives, and established players entering the space. For instance, although Pinecone is widely regarded as the leader in vector databases, it faces competition from open-source projects like Milvus (Zilliz), Weaviate, Chroma, and Qdrant. Additionally, major database companies such as MongoDB and Elastic have all introduced their own vector search capabilities, adding further competitive pressure.
In addition, cloud providers are also in this space. Products like AWS Sagemaker, Azure Machine Learning, and Google Vertex AI all offer fully managed service offerings. These end-to-end solutions are a one-stop shop for building, training, and deploying ML models.
Inference optimization has been a popular but highly competitive space. In the past year, we’ve seen four inference optimization players get acquired by larger companies – Run:ai, Deci, and OctoAI by Nvidia, and Neural Magic by Red Hat. Deci’s investors likely fared well (acquisition price of $300m against $57m total raised), whereas OctoAI’s investors likely saw limited returns (acquisition price of $250m against $133m total raised).
Other notable players in this space include BentoML, Baseten, Fireworks, Lamini, and Together AI. Some of these companies have opted for a more integrated approach by acquiring GPUs themselves and offering a more end-to-end solution. It remains to be seen if these companies can thrive as a standalone public company, or if they will ultimately be acquired, much like their peers.
II. Future Trends to Watch:
Evaluation remains an important but unsolved problem in GenAI. To draw an analogy, consider credit scoring, where credit agencies like Experian, Equifax, and TransUnion assess human creditworthiness. Evaluating creditworthiness is relatively straightforward because the factors involved in determining credit worthiness are well-defined, and human financial behavior is broadly similar. This makes it possible to create standardized metrics.
In contrast to credit scoring, evaluating LLMs is significantly more complex because their applications – such as Q&A, summarization, code generation, and creative writing – are diverse and often industry-specific. Healthcare, for instance, requires different evaluation metrics compared to legal. Consequently, there is no "one-size-fits-all" metric that can effectively assess LLM performance across all contexts, unlike the standardized approach used by credit agencies. Additionally, unlike credit scoring, which is based on objective metrics, LLM evaluation involves subjective factors like creativity and ingenuity, which are harder to quantify.
Startups and AI labs are actively working to address the evaluation challenge. Some startups like Braintrust are trying to build a more domain-agnostic, end-to-end platform equipped with automated evals. OpenAI also recently released SimpleQA, which is a simple evaluation model to check on factuality of the response. Despite these efforts, no universally accepted framework has yet been established for evaluating LLMs effectively.
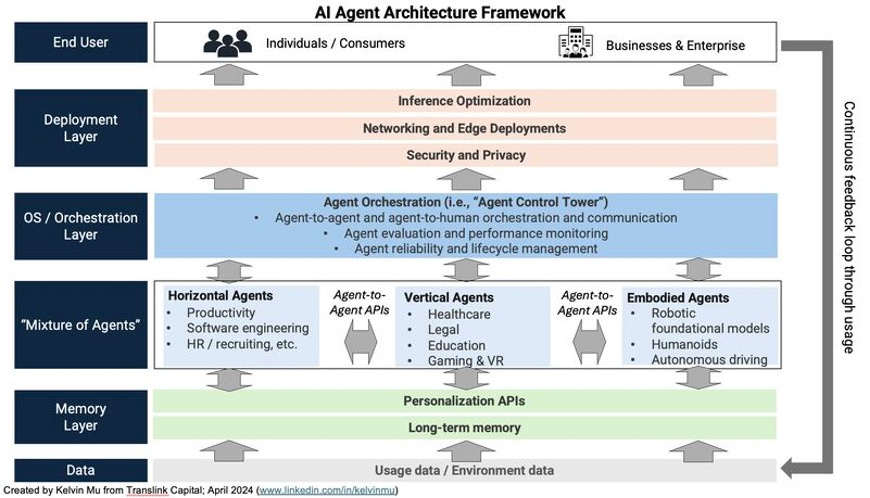
The future of AI tooling will likely revolve around agent. The future of AI tooling is likely to revolve around agents, but building the foundational scaffolding to support a world full of agents is the first step. Take e-commerce agents for example – these are agents that can autonomously make purchases on your behalf one day. Enabling such an agent to work is far more complex than just imbuing it with search and reasoning capabilities. It requires a robust supporting infrastructure: How do agents securely provide credentials? How can one ensure proper authentication to verify that an agent is acting legitimately on a person’s behalf? What new payment system/rail is needed to facilitate agent transactions? We believe the supporting infrastructure around agents, rather than the agents themselves, will be the biggest bottleneck to widespread adoption.
Agent-to-agent collaboration will also take center stage in the future. Just as we have systems and frameworks to evaluate human-to-human interactions, we will need similar ones to manage agent-to-agent interactions. An agent orchestration layer is needed to coordinate agent-to-agent communication. It can also be responsible for assessing agent performance, setting guardrails, and ensuring compliance with their intended mandates. As agents gain more autonomy, ensuring data security and privacy will become increasingly important. New standards and regulations will be needed to govern agent behavior, much like GDPR and similar frameworks that guide human data usage. (see diagram below for one example of an agent framework)
Finally, for agents to succeed at scale, we must develop effective feedback and learning mechanisms. Agents will need to learn from successes and failures to continuously improve. This will require a robust feedback system that enables agents to improve dynamically while maintaining safety and compliance.
We believe the infrastructure scaffolding will need to be developed first before agents can truly proliferate. The orchestration layer will likely be owned by a CSP or a well-funded startup like Emergence AI. Smaller startups can carve out niches by providing ancillary tools like performance monitoring or security, which will feed into this orchestration layer.
III. Noteworthy Startups:
Data:
Cleanlabs, DatalogyAI, Hugging Face, Marqo, , Scale AI, Shakudo, Snorkel AI, SuperAnnotate, Unstructured.io, Weka, Zillis
RAG / Model Customization:
Cohere, Contextual AI, Upstage AI, Vectara
VectorDBs / Embedding Models:
Chroma, Milvus, Pinecone, Qdrant, Voyage AI, Weaviate
Model Serving:
Anyscale, Baseten, BentoML, CentML, Clika AI, Fireworks, Lamini, Lightning AI, Modular, OpenPipe, Replicate, TensorOpera, Together AI
Evaluation and Observability:
Arize AI, Braintrust, DynamoAI, Fiddler AI, Galileo, Galileo AI, Observe, Weights and Biases, WhyLabs
Security:
CalypsoAI, Grey Swan, Hidden Layer, Protect AI, Robust Intelligence (acquired by Cisco), Troj.ai
Agent orchestration/tooling:
Emergence AI, Langchain, MemGPT, Tiny Fish, UnifyApps
APPLICATION LAYER

“At some stage therefore, we should have to expect the machines to take control.”
– Alan Turing
I. Key Takeaways:
GenAI adoption is growing rapidly. Menlo estimates that $4.6 billion has been spent on generative AI applications in 2024, an almost 8x increase from $600 million last year. We expect growth to continue next year as many current projects in POC stage convert to full deployment. This make sense given that when ChatGPT launched in November 2022, most of the corporate budgets for 2023 were already finalized. Therefore, 2024 has been the first year where companies truly had budgets for AI experimentation. Looking ahead, we anticipate AI-related budgets to expand further in 2025 and beyond. A KPMG survey of over 225 C-suite executives revealed that 83% of respondents plan to increase their investments in GenAI over the next three years.
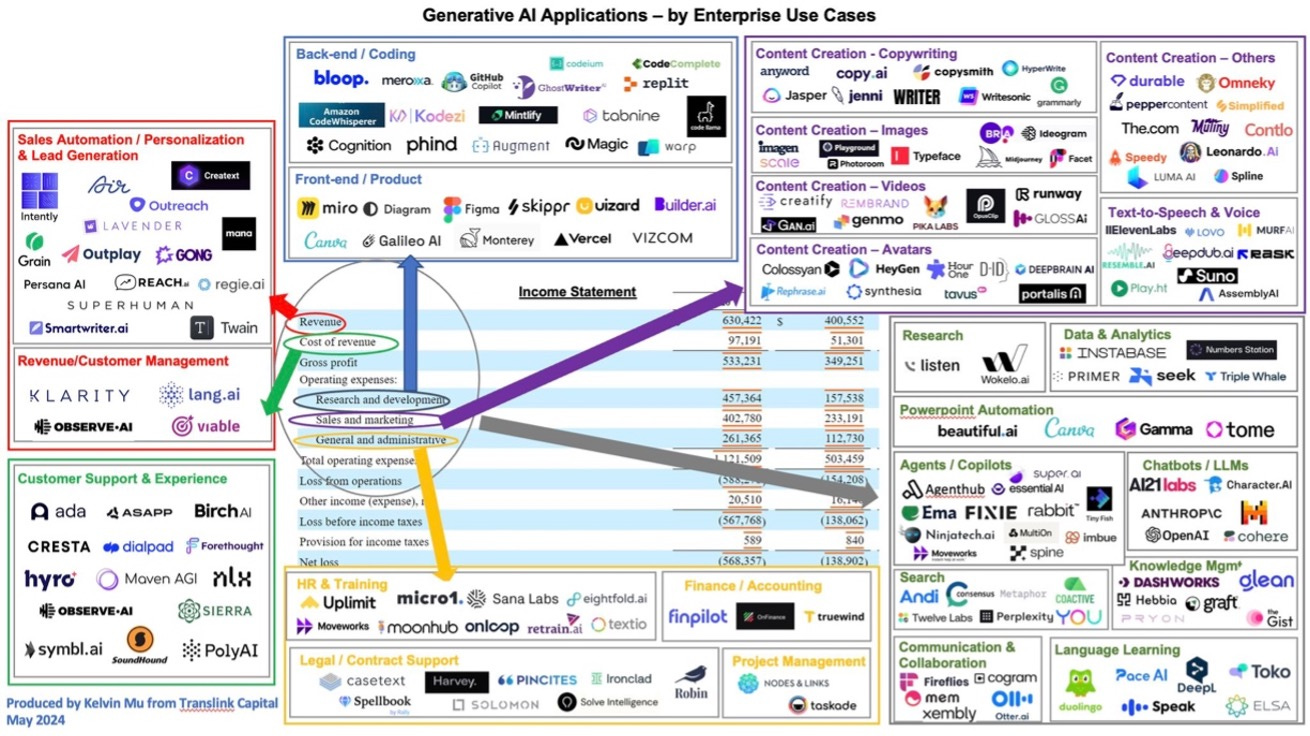
Popular use cases of GenAI right now include code generation, support chatbots/agent, and search:
Code Generation – During Google's latest earnings call, it was revealed that 25% of the company's code is now generated by AI. Microsoft GitHub Copilot, the leading player in this space, has reached ~$300 million ARR and now accounts for 40% of Github’s revenue growth. Several startups, like Cursor, Poolside, Codeium, and Cognition have also entered the market, collectively raising over $1 billion to challenge GitHub’s dominance. While some startups have had impressive traction (~$50m+ ARR), most remain in the early stages of commercialization.
Search – Perplexity has emerged as one of the most recognized startups in GenAI, and have been innovating quickly with features such as Perplexity Finance and Perplexity Shopping Assistant. However, competition is expected to intensify as OpenAI has ChatGPT Search and Meta introduces its own AI-powered search engine. Perplexity’s rumored $50 million ARR is an impressive milestone for a startup of its age, but still represents only 0.025% of Google’s $200 billion search revenue, highlighting both the immense scale of competition and the significant growth potential ahead. It remains to be seen if Perplexity’s push into advertising can help it further chip away at Google’s share in search.
Agents – Agent startups have been gaining traction, particularly those in customer support and sales & marketing. Companies such as Sierra, Maven AGI, and Ema are targeting enterprises, while others like 11x, Artisan, and StyleAI focus more on SMB and mid-market. Larger players are also entering the space, typically with a more horizontal platform approach: Google has Vertex AI Agent Builder, Microsoft has Copilot Studio Agent Builder, Amazon has Amazon Bedrock, and Salesforce has Agentforce. Currently, the agents we’ve seen can handle only relatively simple tasks, but as foundational models improve, especially with advanced reasoning capabilities like those in OpenAI’s o1 model, we expect them to become more capable.
GenAI is transforming SaaS business models. Tanay Jaipuria from Wing Capital noted in his recent article that GenAI is leading to companies adopting more usage-based pricing. For example, Salesforce is charging $2 per conversation for their Agentforce agent while intercom is charging $0.99 per ticket resolution. Just as SaaS revolutionized the software industry by combining technological innovation with a business model innovation (shift from license & maintenance to recurring subscriptions), we believe AI too has the potential to drive another wave of business model innovation.
Enterprises realizing real ROI from GenAI. AI is delivering tangible value for enterprises. For instance, Klarna reported that its AI-powered agents performed the equivalent work of 700 customer service representatives. Despite a 27% increase in revenue, Klarna reduced its headcount from 5,000 to 3,800, with plans to cut further to 2,000. These reductions were driven not by declining growth but by efficiency gains from AI. If similar productivity improvements (~5%) were replicated across the Global 2000, which collectively generates ~$52 trillion in revenue, the potential value creation could reach $2.5 trillion.
Ultimately, investing in AI application companies is not that different from traditional software When investing in AI application startups, a crucial question we ask ourselves is whether improvements to foundational models will leave the startup better or worse off. Simple wrapper companies that rely mostly on the strength of underlying models are likely to lose out; however, we believe those that begin with a deep understanding of the customer journey and associated workflows are likely to benefit. It's akin to building a car: focus on developing the surrounding components first - chassis, interior, software, etc. - and simply swap out the engine as better ones become available, rather than attempting to build out the engine yourself.
Ultimately, the key differentiator for an AI-native application company is no different from that of a traditional SaaS application company – it’s about truly understanding the pain points of your users, meeting them where they are, and delivering a delightful experience for them. The AI is just an enabler, not the differentiator.
The robotics space is seeing renewed interest, fueled by the potential to develop foundational models similar to LLMs for robotics. The latest generation of robotics startups is moving away from heuristic and rule-based programming, focusing instead on end-to-end neural networks. Telsa’s latest FSD software is an example of an end-to-end neural network, relying mostly on vision and data rather than explicitly coded controls.
However, robotics continues to face a significant data bottleneck, and various techniques are being explored to address this challenge.
While imitation learning and teleoperations offer high-quality data, they may not be scalable on their own. Recently, the use of videos and simulations for training has emerged as another promising avenue, with Nvidia Issac Sim and some startups working on this. Conceptually, Google’s RT-2 model demonstrated the potential for generalized robotics performance by leveraging a large model trained on internet-scale vision and language data and fine-tuning it with a smaller set of robotics data.
The primary challenge in simulation lies in creating realistic representations of the ground truth to minimize the sim2real gap. This is particularly difficult because robots come in diverse embodiments and form factors, making data collection and standardization challenging. Ultimately, we believe no single method is likely to solve all these challenges; an ensemble of techniques involving teleoperations, simulation, and video will be required to make it work. For further reading on this topic, see this excellent article by Spectrum.ieee.
II. Future Trends To Watch:
“Services-as-a-software” – AI presents an opportunity to disrupt not just the $400 billion global SaaS market but also the $4 trillion services market. Many jobs today involve repetitive tasks, making them ideal candidates for AI-driven automation. Considering the sheer scale of these markets, the potential impact is clear:

In total, this represents ~120 million workers and almost $4 trillion worth of salaries. For a more detailed analysis on this topic, see this article from Joanne Chen and Jaya Gupta from Foundation Capital.
“Computer Use” is a major inflection point – Anthropic recently introduced “computer use”, which allows developers to direct Claude to use computer in an agentic manner - clicking buttons, typing text, etc. Claude looks at screenshots of what’s visible to the user, then calculates how many pixels it needs to move the cursor to click on the correct location. (For an in-depth case study of computer use, see this paper)
Broadly speaking, there are two approaches to enabling AI agents to perform tasks. The first is API-based, where tasks are broken down into subtasks and executed by chaining together API calls. The second, as seen with Anthropic’s “computer use” is the UI-based approach, which leverages vision and reinforcement learning to interact directly with browsers to execute tasks. In other words, it teaches the model to use computers the way humans do. While the latter approach is theoretically simpler in its lower-level end-to-end approach, it requires more training data and may be computationally more expensive. The end state may indeed be vision-based, but for now, a hybrid approach combining both methods may be required to optimize performance and cost. This is akin to what happened in the full self-driving (FSD) world where end-to-end neural nets relying solely on vision slowly replaced rule-based controls.
Computer use is a significant breakthrough for robotic process automation (RPA). Traditional RPA tools have traditionally faced challenges due to its fragility, as workflows often broke when interfaces changed, requiring constant maintenance. With Anthropic’s computer use, AI models can now adapt to diverse interfaces, reducing the dependency on hard-coded scripts. This breakthrough has already had an impact: UiPath quickly integrated Claude 3.5 Sonnet into three of its key products following Anthropic’s announcement of computer use. This swift adoption underscores how transformative computer use could be in driving the next wave of RPA and intelligent automation. However, we think it’s still early - to use the FSD analogy again, we believe intelligent automation is still in the L1/L2 phase. For a more detailed discussion on RPA, check out this article by Kimberly Tan from A16z.
New hardware form factors. This year has seen the rise of novel hardware form factors aimed at complementing or even replacing smartphones. Despite the excitement, success has been limited so far. For instance, Humane’s AI-powered wearable pin has generated just over $9 million in lifetime sales, despite raising $200 million in funding. Worse, daily return rates are reportedly outpacing new sales. Similarly, the Rabbit R1 has faced extremely poor reviews.
The one notable success story has been the second-generation Meta + Ray-Ban smart glasses. These devices have outsold the previous generation’s two-year sales figures within just a few months, earning generally positive reviews. Meanwhile, major research labs and tech incumbents are also exploring this area. OpenAI, for example, recently hired Caitlin Kalinowski, a former AR hardware leader at Meta, to oversee their robotics and consumer hardware. In addition, Apple design icon Jony Ive has partnered with Sam Altman on a new AI hardware project. The potential to combine large GenAI with new hardware form factors represents an exciting frontier.
Models with enhanced inference-time reasoning capabilities can tackle increasingly complex scientific challenges. Some of the most promising opportunities in this space lie in drug discovery/biomedicine, material sciences, and physics/robotics. In a major nod to open-source, Google DeepMind recently released the code and weights for AlphaFold 3. This surprise announcement followed just weeks after the system’s creators, Demis Hassabis and John Jumper, were awarded the 2024 Nobel Prize in Chemistry for their contributions.
In the scientific domain, startups may pursue various monetization paths: Some choose to offer their tools as SaaS platforms, others pursue a licensing model, and some may even act as principal agents, directly bringing their solutions to market to capture a greater portion of the TAM.
Just as SaaS evolved from horizontal to vertical solutions, we anticipate a similar transition in the AI space. Early in a market's lifecycle, horizontal tools gain traction quickly due to their broad appeal to a large market. However, as the market matures and competition increases, startups often move towards specialized, vertical or domain-specific solutions to differentiate themselves. In AI, this shift to verticalization appears to be happening more quickly than in SaaS for several key reasons:
AI thrives on domain-specific data: AI performs best when trained on data specific to an industry or use case. Many industries have highly domain-specific data sets, making specialized or verticalized training more effective. For instance, in RAG, understanding domain context is critical for retrieval accuracy.
Crowded horizontal market: Unlike the early days of SaaS, many well-established incumbents are already heavily investing in GenAI and launching horizontal solutions. These incumbents are typically already the system of record for whatever use case they are targeting, be it Salesforce for CRM, SAP for ERP, or others. This gives incumbents a substantial edge in distribution and integration. For startups, targeting verticalized or specialized markets may allow them to carve out a more defensible position that can lead to a better chance of success.
Regulatory stringency in key industries: Regulated industries like healthcare, legal, and finance have stringent regulatory requirements. These requirements are most effectively met through verticalized approaches tailored to the unique requirements of each industry.
GenAI consumer companies have yet to breakout. Many of the leading AI consumer startups ended up being acquired this year. For example, we observed two acquihires in the consumer GenAI space – Google’s deal with Character.ai and Microsoft’s deal with Inflection. We believe consumer GenAI applications have yet to break out due to two primary reasons:
First, there hasn’t been a killer consumer use case beyond chatbots like ChatGPT and Perplexity. While Character.ai has arguably achieved product-market fit, its relatively narrow demographic appeal—over half of its users are aged 18 to 24—limits its broader potential. We believe the next transformative consumer application will be a highly capable personal assistant (a smarter Siri), with the longer-term vision being personalized digital twins for everyone.
Second, successful consumer applications often require viral adoption in the beginning, sometimes driven by upfront usage subsidies by the company. However, the current cost of tokens – especially for multimodal models – remains too high for such mass subsidization to be economically feasible. As token costs decrease and/or more workloads move to the edge, we anticipate a new wave of GenAI consumer companies emerging.
III. Noteworthy Startups:
Developer / Code Gen:
Augment Code, CodeComplete, Codeium, Cognition, Cursor, Magic.dev, Poolside, TabbyML, Tabnine, Tessl
Enterprise Productivity:
Consensus, Dust.ai, Exa, Fireflies.ai, Glean, Highlight, Mem, Otter.ai, Read.ai, Taskade, Wokelo AI
Consumer:
Genspark, MultiOn, Liner, Ninjatech.ai, Perplexity, Simple AI, You.com
Multi-modal:
Black Forest Labs, Captions, Coactive, Creatify, Deepbrain, Descript, Heygen, Ideogram, Luma, Openart.ai, Opus Clip, PhotoRoom, Runway, Synthesia, Viggle AI
Next-gen RPA:
Automat, Caddi, HappyRobot, Orby, Sola, Tektonic AI
General Robotics:
ANYbotics, Bright Machines, Field AI, Hillbot, Path Robotics, Physical Intelligence, Skild AI, Swiss-Miles, World labs
Humanoid Robotics:
1x Technologies, Figure AI
General Agents/Copilots:
DeepOpinion, Ema, Factory AI, Gumloop, Jasper, Lyzr, Relevance AI, Sierra, SquidAI, Stack AI, Tektonic AI, Wordware, Writer
HR/Recruiting:
ConverzAI, Eightfold, Jobright.ai, Mercor, Micro1, Moonhub
Customer Support:
AptEdge, Cresta, Decagon, Maven AGI
Sales and Marketing:
11x, Adsgency, Artisan AI, Bounti.ai, Connectly AI, Typeface, StyleAI, Mutiny, Nectar AI, Nooks, Omneky, Rox, Simplified
Product Design and Engineering:
Ambr, Skippr, Uizard, Vizcom
Chip Design:
Astrus, Mooreslab
Presentation Editing:
Beautiful.ai, Gamma, Tome
Vertical Specific- Healthcare:
Abridge, Ambience Healthcare, Atropos Health, Cair Health*, Hippocratic AI, Hyro, Nabla, Scribenote, Segmed.ai, Slingshot AI, Suki AI, Tennr
Vertical Specific - Finance and Procurement:
AskLio*, Auditoria.ai, Finpilot, Hebbia, Klarity, Kipoparts, Linq Alpha, Menos AI, Rogo, Spine AI*
Vertical Specific - Legal:
Casetext (Thomson Reuters), Cicero, EvenUp, Genie AI, Harvey AI, Leya, Robin AI, Solomon AI, Solve Intelligence*, Spellbook/Rally
Vertical Specific - Education and Language:
Elsa, Eureka Labs, MagicSchool AI, Pace AI, Praktika, Riiid, Sana, Speak, Uplimit*
Vertical Specific - Gaming and Entertainment:
Altera, Inworld AI
Vertical Specific - Compliance:
Greenlite, Norm AI
Vertical Specific - Real Estate:
Elise AI
Vertical Specific - Mobility:
Carvis.AI, Revv
*Denotes Translink Capital Portfolio Company
AI INVESTMENTS AND M&A
AI Investments:
Year-to-date (YTD) AI investments have exceeded $60 billion, now representing more than one-third of all venture funding. The largest rounds continue to be in the infrastructure and model layers, with major raises from OpenAI ($6.6B), xAI ($5B), Anthropic ($4B), SSI ($1B), and CoreWeave ($1B). The growing compute demands remain a key driver, with OpenAI alone expected to spend $3 billion on training compute this year.
Some application companies, particularly those in the code generation space, have also raised substantial rounds as they pre-train their own code generation models. Other areas that received significant investor attention include AI chips, AI clouds, robotics foundational model, and enterprise AI. For a full list of AI startups that have raised more than $100 million this year, check out this article by TechCrunch.
Investor demand for AI startups remains strong, with many companies securing significant funding early in their lifecycle. Startups like SSI and World Labs have already reached unicorn status, driven by the strong pedigree of their founding teams. While overall AI valuations remain high –with an average revenue multiple of 26x – investors have become more selective due to the sheer volume of new startups building in this space. For instance, AI startups represented 75% of the most recent YC Summer batch.
Strategic investors like Nvidia and the CSPs continue to show strong interest in AI startups, driving up overall valuations and increasing competition for financial VCs. CSPs are sitting on all time cash balances that need to be reinvested back into growth. For example, Amazon just announced another $4 billion investment in Anthropic.

M&A:
Rise of “reverse acquihires”. This year witnessed the rise of “reverse acquihires” where an incumbent hires a substantial portion of a startup’s team and sometimes licenses its technology, bypassing the complexities of a full acquisition. This strategy allows major tech companies to bolster their AI capabilities while avoiding regulatory scrutiny. Key examples included:
Microsoft / Inflection AI – Microsoft recruited key personnel from Inflection AI, most notably CEO Mustafa Suleyman, who now oversees Microsoft’s entire AI portfolio, including Copilot, Bing, and Edge, and reports directly to Nadella. Given the scope of Suleyman’s role, the price tag may have been worth it.
Amazon / Adept AI – Amazon acquired two-thirds of Adept AI’s workforce, including CEO David Luan, and secured a non-exclusive license to the company’s foundation model. The company received $25 million for the licensing deal, while their investors, who put $414 million into the company, will roughly recoup their investment.
Google / Character.ai – With the acquisition, Google brought on CEO Noam Shazeer, President Daniel De Freitas, and about 30 of Character.ai’s 130 employees in a deal reportedly valued at $2.7 billion—more than 2.5x the company’s last valuation.
Total M&A activity (estimated to be ~$2-3 billion) was relatively subdued this year. This was similar to last year where there were only three major acquisitions (MosaicML, CaseText, Neeva). Interestingly, 5 of the 8 notable acquisitions this year were in the tooling layer, and 4 of them were in the inference optimization space (OctoAI, Deci, Run:ai, Neural Magic). Notable acquisitions include:
In the short term, we may seem limited M&A given difference of expectation between acquirers and startups. Despite strong interest from acquirers, M&A activity may remain limited due to a disconnect in valuation expectations. A corporate development executive at a leading SaaS company highlighted that while they were interested in acquiring AI startups, there was often a significant valuation gap. Incumbents acquirers believe they should receive a discount due to their existing customer base and distributional advantages, while AI startups and their investors expected a premium, driven in part by the high market valuations. This mismatch in expectations may continue to dampen M&A activity in the near term.
M&A consolidation will likely happen towards the end of the cycle. In the telecom/internet era, most M&A transactions occurred in the second part of the decade. In 1999 alone, there was over $3 trillion dollars’ worth of M&A transactions. Typically, consolidation happens when the economics become more mature and the winners are largely determined already. The lack of significant consolidation in AI today is another indicator that we are still in the early stages.
OTHER AI TRENDS: SOVERIGN AI, COPYRIGHT, AND REGULATIONS
Sovereign AI:
As AI proliferates, the concept of Sovereign AI is drawing increasing attention. A central concern for many governments is whether they are comfortable with sensitive data being processed on platforms like ChatGPT, which are controlled by other countries. The broader geopolitical rift is increasingly mirrored within the microcosm of the AI world, resulting in the emergence of separate AI ecosystems across different regions.
A key consideration is: at which layers of the AI stack will sovereign AI emerge? Current developments suggest it will primarily manifest in the infrastructure and model layers. For investors, this presents unique opportunities to back region-specific startups as distinct ecosystems arise globally. Success may not require backing the global leader; instead, regional champions could thrive in local markets as well.
Let’s briefly review some of the AI developments and strategies across major regions:
US: The U.S. continues to lead innovation in GenAI across all layers of the stack. Major AI labs like OpenAI, Anthropic, and Meta dominate advancements, thanks to a deep talent pool and world-class academic institutions. On the infrastructure side, U.S. hyperscalers provide unmatched compute power, while Nvidia maintains its lead in hardware. This integrated ecosystem gives the U.S. a considerable advantage in the short to medium term.
China: In response to semiconductor export controls, China is prioritizing its domestic chip industry. In May, the government announced a $47.5 billion state semiconductor investment fund to bolster its chip industry. Although hardware lags behind, Chinese LLMs, such as Alibaba's Qwen and DeepSeek, remain highly competitive. Surprisingly, China leads in generative AI adoption, with 83% of companies testing or implementing the technology – surpassing the U.S. (65%) and the global average (54%).
Europe: Europe’s stringent regulations, like the EU AI Act, may stifle AI innovation. Regulations have already caused U.S. tech giants, including Meta and X, to delay AI rollouts in the region. Apple, too, opted not to launch Apple Intelligence on its latest iPhone in Europe for similar reasons. While Europe boasts standout labs like Mistral AI, their ability to compete independently with U.S. CSPs and AI labs remains unclear for now, especially in light of the regulatory handicap.
Japan: Japan is experiencing significant growth in data center infrastructure. Oracle recently announced an $8 billion investment in new data centers, following Microsoft’s $3 billion commitment. At the model layer, Sakana AI has emerged as a key player, recently closing a $200 million Series A round (Translink is an investor). Japan’s government is fostering AI innovation with light regulations and strong support, recognizing AI as a critical technology to address its aging population and growing need for automation. The large market opportunity combined with government support positions Japan as a promising market for AI innovation and startups.
AI and Copyright:
· The intersection of AI and copyright law is becoming a critical issue as genAI content becomes more pervasive. Recent controversies, such as claims that Apple, Nvidia, and Anthropic used YouTube videos without permission to train AI models, have highlighted concerns of intellectual property violations. Similarly, major record labels like Universal, Sony, and Warner are suing AI startups such as Suno and Udio for using copyrighted music to generate content. These disputes highlight the tension between innovation and the safeguarding of creative assets.
The news industry is also grappling with these challenges. News Corp recently sued Perplexity AI over alleged false attributions and hallucinations tied to its publications, while simultaneously striking a $250 million partnership with OpenAI to provide access to its archives. These contrasting moves reflect both the risks and opportunities AI presents to traditional media.
Despite these disputes, some platforms are leveraging AI to enhance creativity and compliance. For example, Spotify is using generative AI to personalize user experiences while adhering to copyright laws. This suggests that AI and intellectual property can coexist, provided there are clear frameworks.
Some companies are working to address this issue. An interesting startup is Tollbit which is helping to bridge the gap between publishers and AI developers by enabling publishers to monetize their content. Another one is ProRata.ai which is working on attribution technology to enable fair compensation to content owners. Striking a balance between innovation and protecting creators' rights will be a crucial topic in the years ahead.
AI Regulations:
The EU AI Act represents the first comprehensive framework of its kind, categorizing AI systems by risk levels: unacceptable, high, limited, and minimal. Systems considered "unacceptable risk," like social scoring by governments or manipulative AI, are banned, while "high-risk" systems in critical sectors face stringent requirements.
Key provisions include mandatory compliance assessments, robust documentation, and oversight by a European AI Board. Non-compliance could result in fines of up to €30 million or 6% of global revenue.
Following his re-election in November 2024, President Donald Trump announced plans to repeal Biden's AI executive order upon taking office. The Trump administration is arguing that the existing regulations stifle innovation and impose unnecessary burdens on businesses. Instead, they advocate for a more industry-friendly approach, emphasizing voluntary guidelines and reduced federal oversight to promote AI development.
CONCLUSION
If you’ve made it all the way through to here – let me be the first to congratulate you. I know that was a lot to digest. If I had to distill everything into five key takeaways, they would be:
The entire infrastructure stack is undergoing a significant overhaul, reminiscent of the internet and cloud buildouts. The demand for inference is only beginning to accelerate and will be driven by increasing adoption of GenAI, new multimodal applications, and evolving model architectures.
As scaling laws begin to plateau, model development is shifting away from large pre-training datasets towards inference-time reasoning. This shift enables models to tackle more complex reasoning tasks. Concurrently, the rise of smaller, specialized SLMs promises greater efficiency and flexibility for users.
For the first time, AI is delivering tangible ROI in enterprise settings, with use cases like code generation, customer support, and search driving measurable impact. The next frontier lies in the proliferation of AI agents, but their true potential will only be realized after we build the underlying scaffolding required to enable multi-agent interactions.
Investment in AI continues to grow, particularly in the infrastructure and foundational model layers. Most exits will be through M&A but high investor expectations could clash with market realities, potentially impacting future valuations.
The rapid adoption of AI has outpaced regulatory frameworks, sparking debates over topics like copyright and intellectual property. Meanwhile, nations are increasingly framing AI as a matter of sovereignty, leading to greater focus on the regionalization of AI ecosystems.
It’s been only 24 months since ChatGPT took the world by storm – an event Jensen Huang of Nvidia aptly described as the "iPhone moment" for AI. In this short time, we've witnessed some of the fastest innovation in modern history. Massive infrastructure investments, daily breakthroughs in foundational models, and an insatiable appetite for enterprise adoption have converged to reshape not only technology but the very way our society operates.
As we move into 2025, one thing is clear: this is only the beginning. There’s still so much left to build and discover. If history has taught us anything, it’s that progress is rarely linear – surprise breakthroughs will always occur alongside unexpected setbacks. For everyone living through this these pivotal years of AI – entrepreneurs, technologists, students, and investors alike – our mission is clear: to engage deeply, innovate responsibly, and create a future where humans and technology can coexist in harmony. In doing so, we leave a better world for our future generations, just as our predecessors aspired for us.
SOURCES USED
1. https://blog.google/inside-google/message-ceo/alphabet-earnings-q3-2024/#search
3. https://www.sequoiacap.com/article/ais-600b-question/
4. https://www.goldmansachs.com/insights/top-of-mind/gen-ai-too-much-spend-too-little-benefit
5. https://www.marketwatch.com/story/is-the-world-in-an-ai-bubble-money-managers-are-split-3967101a
7. https://kelvinmu.substack.com/p/ai-are-we-in-another-dot-com-bubble
8.https://www.reddit.com/r/LocalLLaMA/comments/1gpr2p4/llms_cost_is_decreasing_by_10x_each_year_for/
9. https://techcrunch.com/2024/09/12/openai-unveils-a-model-that-can-fact-check-itself/
12. https://www.cnbc.com/2024/09/30/cerebras-files-for-ipo.html
13. https://www.goldmansachs.com/insights/articles/AI-poised-to-drive-160-increase-in-power-demand
16. https://www.theverge.com/2024/10/29/24282843/openai-custom-hardware-amd-nvidia-ai-chips
20. https://www.alibabacloud.com/en/solutions/generative-ai/qwen?_p_lc=1
21. https://www.deepseek.com/
22. https://blogs.microsoft.com/blog/2020/01/16/microsoft-will-be-carbon-negative-by-2030/
25. https://arxiv.org/abs/2206.14486
26. https://azure.microsoft.com/en-us/blog/introducing-phi-3-redefining-whats-possible-with-slms/
27. https://deepmind.google/technologies/gemini/flash/
28. https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
29. https://arxiv.org/pdf/2409.00088
30. https://openai.com/index/introducing-openai-o1-preview/
31. https://medium.com/@tsunhanchiang/openai-o1-the-next-step-of-rl-training-692838a39ad4
33. https://finance.yahoo.com/news/openai-closed-funding-round-raising-161842066.html
34. https://ai.meta.com/blog/llama-usage-doubled-may-through-july-2024/
38. https://openai.com/index/introducing-chatgpt-search/
39. https://github.com/openai/swarm
40. https://qwenlm.github.io/blog/qwen2.5-coder-family/
41. https://techcrunch.com/2024/11/27/alibaba-releases-an-open-challenger-to-openais-o1-reasoning-model/
44. https://arxiv.org/abs/2402.15391
45. https://www.amazon.science/code-and-datasets/chronos-learning-the-language-of-time-series
48. https://sakana.ai/ai-scientist/
49. https://menlovc.com/2024-the-state-of-generative-ai-in-the-enterprise/
50. https://mitsloan.mit.edu/ideas-made-to-matter/tapping-power-unstructured-data
51. https://www.braintrust.dev/blog/getting-started-evals
52. https://openai.com/index/introducing-simpleqa/
53. https://kpmg.com/us/en/media/news/gen-ai-survey-august-2024.html
54. https://www.microsoft.com/en-us/investor/events/fy-2024/earnings-fy-2024-q4
55. https://www.theverge.com/2024/10/28/24282017/meta-ai-powered-search-engine-report
56. https://www.statista.com/statistics/266249/advertising-revenue-of-google/
57. https://www.perplexity.ai/hub/blog/why-we-re-experimenting-with-advertising
58.

60. https://www.intercom.com/help/en/articles/8205718-fin-ai-agent-resolutions
62. https://www.forbes.com/lists/global2000/
63. https://electrek.co/2024/01/22/tesla-releases-fsd-v12-last-hope-self-driving/
64. https://developer.nvidia.com/isaac/sim
65. https://deepmind.google/discover/blog/rt-2-new-model-translates-vision-and-language-into-action/
66. https://spectrum.ieee.org/solve-robotics
67. https://foundationcapital.com/ai-service-as-software/
68. https://www.anthropic.com/news/3-5-models-and-computer-use
69. https://arxiv.org/pdf/2411.10323
71. https://a16z.com/rip-to-rpa-the-rise-of-intelligent-automation/
72. https://www.theverge.com/2024/8/7/24211339/humane-ai-pin-more-daily-returns-than-sales
73. https://www.theverge.com/2024/5/2/24147159/rabbit-r1-review-ai-gadget
76. https://www.theverge.com/2024/9/21/24250867/jony-ive-confirms-collaboration-openai-hardware
77. https://github.com/google-deepmind/alphafold3
78. https://www.nature.com/articles/d41586-024-03214-7
81. https://aventis-advisors.com/ai-valuation-multiples/
83. https://pitchbook.com/news/articles/y-combinator-demo-day-ai-startups-analysis
85. https://techcrunch.com/2024/06/28/amazon-hires-founders-away-from-ai-startup-adept/
87. https://www.redhat.com/en/about/press-releases/red-hat-acquire-neural-magic
89. https://www.calcalistech.com/ctechnews/article/bkj6phggr
90. https://blogs.nvidia.com/blog/runai/
91. https://techcrunch.com/2024/05/06/docusign-acquires-ai-powered-contract-management-firm-lexion/
93. https://www.canva.com/newsroom/news/leonardo-ai/
94. https://www.latimes.com/archives/la-xpm-1999-dec-02-fi-39632-story.html
98. https://www.tomsguide.com/ai/apples-refusing-to-launch-apple-intelligence-in-the-eu-heres-why
101. https://sakana.ai/series-a/
103. https://www.theverge.com/2024/6/24/24184710/riaa-ai-lawsuit-suno-udio-copyright-umg-sony-warner
105. https://venturebeat.com/ai/openai-partners-with-wall-street-journal-publisher-news-corp/

ABOUT THE AUTHOR
Kelvin is a Principal at Translink Capital focused on artificial intelligence and machine learning. He looks at opportunities across the AI stack, including in infrastructure, foundational models, tooling and applications. Prior to joining Translink, Kelvin held various roles in business operations, strategy consulting, and investment banking in the United States and Canada. Kelvin holds an MBA from the Haas School of Business at UC Berkeley and a BA from the Ivey School of Business at Western University. In his spare time, Kelvin’s an avid reader and aims to read one non-fiction book per week. He’s also an aspiring amateur golfer who is on a quest to become a self-taught scratch golfer. He writes regularly about trends in AI, technology and business.
For the latest content, please follow him at:
LinkedIn: https://www.linkedin.com/in/kelvinmu/
Substack:

ABOUT TRANSLINK CAPITAL
Translink Capital is an early-stage VC firm founded in 2007 and based out of Palo Alto, California. Managing over $1 billion in AUM, Translink is backed by over 30 corporates from Asia, including multinationals such as Hyundai, NEC, LG, Foxconn, Sompo, and Japan Airlines. In addition to providing capital to startups, the firm focuses on connecting portfolio companies to their corporate LPs as customers or channel partners. The firm invest across the entire technology stack and typically write checks up to $10 million. For more information, please visit www.translinkcapital.com.
Wonderful content. Gracie Mile! ;L)
This was so comprehensive and user friendly. Thank you!